Bigtable
A NoSQL wide-column single-table database
Paul Krzyzanowski
November 7, 2022
Goal: How can we build an ultra-high performance, low-latency storage service for large-scale structured and semi-structured data?
Introduction
A relational database is a type of database that stores and provides access to data elements that are related to one another. Its key feature is the use of tables, where data is stored in rows and columns. The rows of a table represent a list of items and the columns represent particular attributes of that data. For example, the columns for a table of students might contain a student ID number, first name, last name, email address, and phone number while each row represents a unique student. One column in the table will usually contain a unique identifier for each row and be referred to as a primary key, allowing a specific row to be referenced uniquely. For example, a student’s ID in the student table may be a primary key. A relational database will typically contain multiple tables. For instance, our school example may have tables of students, teachers, courses, and grades.
Queries, mostly performed in SQL (Structured Query Language) allow one to extract specific columns from a row where certain conditions are met (e.g., a column has a specific value). One can perform queries across multiple tables (this is the “relational” part of a relational database). A table of grades may include a student’s ID number, course number, and grade. We can construct a query that looks up a student’s grades by name by searching for the ID number in the student table and then finding all occurrences of that ID number in the grade table. We can further show the name of each corresponding course by looking up the course ID number in the courses table. Each row in a table represents a record with a unique identifier known as a primary key, and each column represents a particular attribute of the data. For example a table of grades may use a student’s ID number as a primary key (since that’s unique)
With relational databases, we expect ACID guarantees: that transactions will be atomic, consistent, isolated, and durable. This includes operations that access or modify multiple fields, multiple rows, and multiple tables. The CAP theorem proved that is not possible to guarantee consistency while providing high availability and network partition tolerance. Partitions are unavoidable in distributed systems, so the design choice is between high availability and consistency. ACID databases choose consistency, which usually involves locking and waiting: a transaction needs to update all replicas and cannot have some concurrent transactions work with old data while others access new data. In distributed architectures, we often choose to give up consistency in order to provide high availability. This makes ACID databases unattractive for highly distributed environments and led to the emergence of alternate data stores that are targeted to high availability and high performance. These data stores are often referred to as NoSQL databases.
Another aspect of conventional database systems is that they often do not do well with tables containing huge amounts of columns or even fields that contain huge amounts of data. Adding additional fields to a table (hence changing the schema of the database) can be a time-consuming task.
Here, we will look at the structure and capabilities of Bigtable. It is not a relational database; it is just a table but one that is designed to support efficient lookups and handle data on a huge scale. It is also designed as a wide-column store. This means that each row of a table can support a huge number of columns and the specific column names may vary from row to row.
Bigtable
Bigtable is a distributed storage system that is structured as a large table: one that may be petabytes in size and distributed among tens of thousands of machines. It is designed for storing items such as billions of URLs, with many versions per page; over 100 TB of satellite image data; hundreds of millions of users; and performing thousands of queries a second.
Bigtable was developed at Google in has been in use since 2005 in dozens of Google services. An open source version, HBase, was created by the Apache project on top of the Hadoop core (using the Hadoop Distributed File System, HDFS, instead of GFS and using Apache Zookeeper instead of Google’s Chubby).
Bigtable is designed with semi-structured data storage in mind. It is a large map where every item is indexed by a row key, column key, and a timestamp. Each value within the map is an array of bytes that is interpreted by the application. Clients can look up a row key and then iterate over all of its columns and over versions of data within each column. Every read or write of data to a row is atomic, regardless of how many different columns are read or written within that row.
It is easy enough to picture a simple table but let us examine a few characteristics of Bigtable and what makes it special:
- map
- A map is an associative array; a data structure that allows one to look up a value to a corresponding key quickly. Bigtable is a collection of (key, value) pairs where the key identifies a row and the value is the set of columns.
- persistent
- The data is stored persistently on disk.
- distributed
- Bigtable’s data is distributed among many independent machines. At Google, Bigtable was built on top of GFS (Google File System)1. The Apache open source version of Bigtable, HBase, is built on top of HDFS (Hadoop Distributed File System) or Amazon S3. The table is broken up among rows, so a sequence of adjacent rows will be managed by the same server. A row itself is never distributed.
- sparse
- The table is sparse, meaning that different rows in a table may use vastly different columns (there could be millions), with many – or even most – of the columns empty for a particular row.
- sorted
- In most databases or object stores, data is not sorted. A key is hashed to find its a position in a table. Bigtable, on the other hand, sorts its data by keys. This helps keep related data close together, usually on the same machine — assuming that one structures keys in such a way that sorting brings the data together. For example, if domain names are used as keys in a Bigtable, it makes sense to store them in reverse order to ensure that related domains are close together. For example:
edu.rutgers.cs
edu.rutgers.nb
edu.rutgers.www
- multidimensional
- A table is indexed by rows. Each row contains one or more named column families. Column families are a way of grouping columns and are defined when the table is first created. Within a column family, one may have one or more named columns. These can be defined dynamically at any time and there is essentially no limit to the number of columns within a column family. All data within a column family is usually of the same type. The implementation of Bigtable compresses all the columns within a column family together. Rows, column families and columns provide a three-level naming hierarchy to identify data. For example:
"edu.rutgers.cs" : { // row
"users" : { // column family
"bjs" : "Bart", // column
"lsimpson" : "Lisa", // column
"homer" : "Homer" // column
}
"sysinfo" : { // another column family
"os" : "Linux 5.4.0", // column
"cpu" : "Xeon E5-2698" // column
}
}
To get data from Bigtable, you need to identify the row and provide a fully-qualified name for a row in the form column-family:column. For example, users:homer or sysinfo:cpu. Since you can have an unlimited number of columns that can be added dynamically, Bigtable provides iterators to allow clients to discover and iterate over all columns within a column family.
- time-based
- Time is another dimension in Bigtable data. Every column family may keep multiple versions of column family data. If an application does not specify a timestamp, it will retrieve the latest version of the column family. Alternatively, it can specify a timestamp and get the latest version that is earlier than or equal to that timestamp.
Columns and column families
Let’s look at a sample slice of a table that stores web pages (this example is from Google’s paper on Bigtable). The row key is the page URL. For example, com.cnn.www.

Various attributes of the page are stored in column families. A contents column family contains page contents (there are no columns within this column family).
A language column family contains the language identifier for the page.
Finally, an anchor column family contains the text of various anchors from other web pages. The column name is the URL of the page making the reference. These three column families underscore a few points.
A column may be a single short value, as seen in the
language column family. This is our classic database view of columns. In Bigtable, however, there is no type associated with the column. It is just a bunch of bytes.
The data in a column family may also be large, as in the contents column
family.
The anchor column family illustrates the extra hierarchy created by having columns within a column family. It also illustrates the fact that columns can be created dynamically (one for each external anchor), unlike column families.
Finally, it illustrates
the sparse aspect of Bigtable. In this example, the list of columns within the
anchor column family will likely vary tremendously for each URL. Each column name within anchor is the name of the URL that contains a link to the URL indicated by the row key. The value of the column is the text on the page that contains the link. For example, cnnsi.com contains a link with the text CNN that links to www.cnn.com. The interesting feature of a wide-column store such as Bigtable is that the name of the column is itself a form of a value. A client can iterate through all the column names within anchor to get a list of URLs that contain links to a specific web page (the row key).
In all, we may have a huge number (e.g., hundreds of thousands or millions) of columns overall but the column family within each row will often have only a tiny fraction of them populated. While the number of column families will typically be small in a table (at most hundreds), the number of columns is unlimited.
Rows and partitioning
A table is logically split among rows into multiple subtables called tablets. A tablet is a set of consecutive rows of a table and is the unit of distribution and load balancing within Bigtable. Because the table is always sorted alphabetically by row, reads of short ranges of rows are efficient: one typically communicates with one or a small number of machines. Hence, a key to ensuring a high degree of locality is to select row keys properly (as in the earlier example of using domain names in reverse order).
Timestamps
Each column family cell can contain multiple versions of content. For example, in the earlier example, we may have several timestamped versions of page contents associated with a URL. Each version is identified by a 64-bit timestamp that either represents real time or is a value assigned by the client. Reading column data retrieves the most recent version if no timestamp is specified or the latest version that is earlier than a specified timestamp.
A table is configured with per-column-family settings for garbage collection of old versions. A column family can be defined to keep only the latest n versions or to keep only the versions written since some time t.
Implementation
Bigtable comprises a client library (linked with the user’s code), a master server that coordinates activity, and many tablet servers. Tablet servers can be added or removed dynamically. If the master dies, another master can take over.
The master assigns tablets to tablet servers and balances tablet server load. It is also responsible for garbage collection of files in GFS and managing schema changes (table and column family creation). As such, a tablet server is responsible for tablets but the tablets do not necessarily live on that node since any node can access any data within GFS.
Each tablet server manages a set of tablets (typically 10–1,000 tablets per server). It handles read/write requests to the tablets it manages and splits tablets when a tablet gets too large. Client data does not move through the master; clients communicate directly with tablet servers for reads/writes. The internal file format for storing data is Google’s SSTable, which is a persistent, ordered, immutable map from keys to values. Rows of data are always kept sorted by the row key.
Bigtable uses the Google File System (GFS) for storing both data files and logs. A cluster management system contains software for scheduling jobs, monitoring health, and dealing with failures.
Chubby
Chubby is a highly available and persistent distributed lock service that manages leases for resources and stores configuration information. The service runs with five active replicas, one of which is elected as the master to serve requests. A majority must be running for the service to work. It uses a Paxos distributed consensus algorithm to keep the replicas consistently synchronized. Chubby provides a namespace of files & directories. Each file or directory can be used as a lock.
In Bigtable, Chubby is used to:
- ensure there is only one active master
- store the bootstrap location of Bigtable data
- discover tablet servers
- store Bigtable schema information
- store access control lists
Startup and growth
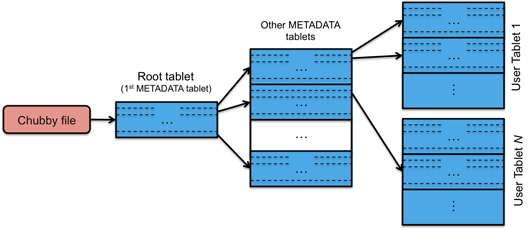
A table starts off with just one tablet. As the table grows, it is split into multiple tablets. By default, a table is split at around 100 to 200 MB.
Locating rows within a Bigtable is managed in a three-level hierarchy. The root (top-level) tablet stores the location of all Metadata tablets in a special Metadata table. This root tablet is simply the first tablet in the set of tablets that comprise the Metadata table. Each Metadata table contains the location of user data tablets. This table is keyed by node IDs and each row identifies a tablet’s table ID and end row. For efficiency, the client library caches tablet locations.
A tablet is assigned to one tablet server at a time. Chubby keeps track of tablet servers. When a tablet server starts, it creates and acquires an exclusive lock on a uniquely-named file in a Chubby servers directory. The master monitors this directory to discover new tablet servers.
When the master starts, it:
- Grabs a unique master lock in Chubby (to prevent multiple masters from starting)
- Scans the servers directory in Chubby to find live tablet servers
- Communicates with each tablet server to discover what tablets are assigned to each server. This is important because the master might be recovering for a failed master and tablets have already been allocated to tablet servers.
- Scans the Metadata table to learn the full set of tablets
- Track the set of unassigned tablets. These are eligible for tablet assignment and the master will choose a tablet server and send it a tablet load request.
Fault tolerance and replication
Some of the fault tolerance for Bigtable is provided by GFS and Chubby. GFS, for example, provides configurable levels of replication of file data and Chubby’s cell of replicated servers minimizes its downtime.
A master is responsible for detecting when a specific tablet server is not functioning. It does this by asking the tablet server for status of its lock (recall that Chubby grants locks). If the tablet server cannot be reached or has lost its lock, the master attempts to grab that server’s lock. If it succeeds, then it surmises the tablet server is dead or cannot contact Chubby. In this case, the master moves the tablets that were previously assigned to that server into an unassigned state.
When a master’s Chubby lease expires, it kills itself. This does not change the assignment of tablets to servers, however. Google’s cluster management system periodically checks for the liveness of a master. If it detects a non-responding master, it starts one up, which grabs a lock from Chubby. The new master contacts Chubby to find all the live servers goes through the startup phase described earlier.
A Bigtable can be configured for replication onto multiple Bigtable clusters in different data centers to ensure availability. Data propagation is asynchronous and results an eventually consistent model.
References
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber, Bigtable: A Distributed Storage System for Structured Data, Google, Inc. OSDI 2006: The definitive paper on Bigtable.
Google, Overview of Bigtable, Google Cloud Documentation. This describes the current Google Cloud offering of Bigtable. Note that GFS has been replaced with Colossus (a newer distributed file system) and tablet servers are now called Bigtable nodes.
Ilya Grigorik, SSTable and Log Structured Storage: LevelDB, igvita.com, February 26, 2012: _a description of the SSTable (Sorted String Table) used in Bigtable.
Cloud Bigtable: A publicly-available version of Bigtable, part of the Google Cloud Platform
Google, Bigtable for Cassandra users, Google Cloud – Cloud Architecture Center.
Robin Harris, Google’s Bigtable Distributed Storage System](http://storagemojo.com/2006/09/07/googles-bigtable-distributed-storage-system-pt-i/), StorageMojo.com
Apache HBase: An open-source project based on the design of Bigtable.
Understanding HBase and Bigtable, Jumoojw.com
This is an updated version to one that was originally published in November 2011.
-
The current version of Bigtable a Google runs on Colossus, a successor to the Google File System. One of the big changes to GFS in Colossus was that file system metadata is no longer stored on a single server. Instead, it is stored in Bigtable. Yes, that looks like a circular dependency: Colossus is implemented using Bigtable and Bigtable instances run on Colossus! ↩︎